各式各样的验证码
还记得以前那篇《超强验证码》?其实这个世界变态的验证码还有很多,下面是一个列表向像展示了各种稀奇古怪的验证码。不过本文并不单单只是收集这验证码,前面的比较恶搞,后面的会向你展示什么是有accessibility验证码。
完全看不清楚的
这是人类的字符吗?
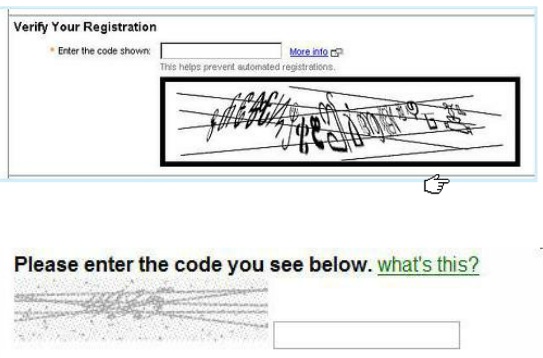
图案中的字母是什么?

 (24 人打了分,平均分: 4.08 )
(24 人打了分,平均分: 4.08 )还记得以前那篇《超强验证码》?其实这个世界变态的验证码还有很多,下面是一个列表向像展示了各种稀奇古怪的验证码。不过本文并不单单只是收集这验证码,前面的比较恶搞,后面的会向你展示什么是有accessibility验证码。
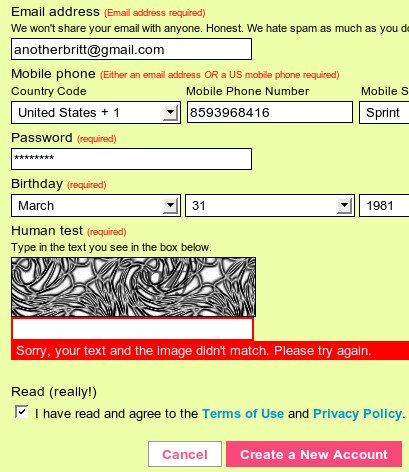
这是人类的字符吗?
图案中的字母是什么?
(24 人打了分,平均分: 4.08 )在《性能调优攻略》里,我说过,要调优性需要找到程序中的Hotspot,也就是被调用最多的地方,这种地方,只要你能优化一点点,你的性能就会有质的提高。在这里我给大家举三个关于代码执行效率的例子(它们都来自于网上)
PHP中Getter和Setter的效率(来源reddit)
这个例子比较简单,你可以跳过。
考虑下面的PHP代码:我们可看到,使用Getter/Setter的方式,性能要比直接读写成员变量要差一倍以上。
<?php
//dog_naive.php
class dog {
public $name = "";
public function setName($name) {
$this->name = $name;
}
public function getName() {
return $this->name;
}
}
$rover = new dog();
//通过Getter/Setter方式
for ($x=0; $x<10; $x++) {
$t = microtime(true);
for ($i=0; $i<1000000; $i++) {
$rover->setName("rover");
$n = $rover->getName();
}
echo microtime(true) - $t;
echo "\n";
}
//直接存取变量方式
for ($x=0; $x<10; $x++) {
$t = microtime(true);
for($i=0; $i<1000000; $i++) {
$rover->name = "rover";
$n = $rover->name;
}
echo microtime(true) - $t;
echo "\n";
}
?>
这个并没有什么稀,因为有函数调用的开销,函数调用需要压栈出栈,需要传值,有时还要需要中断,要干的事太多了。所以,代码多了,效率自然就慢了。所有的语言都这个德行,这就是为什么C++要引入inline的原因。而且Java在打开优化的时候也可以优化之。但是对于动态语言来说,这个事就变得有点困难了。
 (18 人打了分,平均分: 3.72 )
(18 人打了分,平均分: 3.72 )下面是Kristóf Kovács收集的28个Unix/Linux下的28个命令行下的工具(原文链接),有一些是大家熟悉的,有一些是非常有用的,有一些是不为人知的。这些工具都非常不错,希望每个人都知道。本篇文章还在Hacker News上被讨论,你可以过去看看。我以作者的原文中加入了官网链接和一些说明。
iostat, vmstat, ifstat 三合一的工具,用来查看系统性能(我在《性能调优攻略》中提到过那三个xxstat工具)。
官方网站:http://dag.wieers.com/rpm/packages/dstat/
你可以这样使用:
alias dstat='dstat -cdlmnpsy'
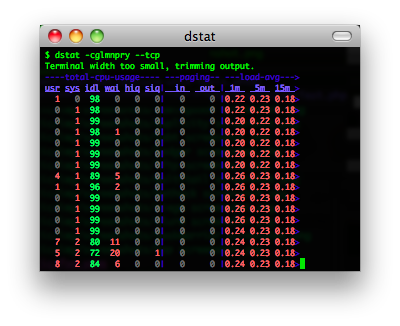
查看网络流量的一个工具
(27 人打了分,平均分: 4.11 )【感谢网友 @innocentim (Twitter) 投稿】
这是一篇翻译练习。力图保留原意。若有不准确处,求速速指出。猛击此处(墙)看原文。作者为Rob Pike,贝尔实验室来的大牛,现在就职于Google。他主导了Go语言的创建工作。下面是正文——
——————————————正文分隔线——————————————
 这是我在2012年6月的Go SF上演讲的文本。
这是我在2012年6月的Go SF上演讲的文本。
这是一个个人演讲。 我承认,虽然面前的团队让Go诞生并延续,但是我的观点并不代表任何其他Go语言小组成员的意见。 我也想感谢Go SF的组织者提供这个和你们交流的机会。
几星期前我被问起:“你在推出Go的过程中遇到的最大的惊奇是什么?”我立即意识到了答案: 虽然我们希望C++程序员意识到Go是个较好的选择,但是令人意外的是,大多数Go程序员来自Python和Ruby这样的动态语言,而很少有来自C++的。
我们——Ken,Robert和我——是C++程序员(译者: Ken也用C++?),当时在为解决我们所写的这类软件产生的问题设计一个新的语言。 这似乎有点自相矛盾,因为别的C++程序员根本不关心这些问题,更不会去设计一个语言。
我今天想说的是关于那些激发我们创造Go的事情,和为什么它本不应令我们如此惊讶。 我保证这些内容更多与Go相关而不是C++,所以即使你不很了解C++你也能跟得上。
回答可以这样归结: 你认为”少即是多”呢,还是”少就是少”?
这里有个比喻,将以真实故事的形式给出。 贝尔实验室中心原来发放3位数号码: 物理研究是111,计算科学研究是127,如此这般。 1980年代早期,一个便笺飞过来说”鉴于你们对研究的理解有所加深,将为你们的号码多加上一位,以便更好地体现你们的工作”。 所以我们中心的号码变成了1127。 Ron Hardin半当真地开玩笑说如果我们真的理解我们的世界更好一点的话,我们将丢掉一位数字,将127变成27。 当然主管没听到这个笑话(这也不是我们希望的),但是我想这里面有点值得思考的东西。 少即是多。 你理解得越好,你将变得越简洁。
(31 人打了分,平均分: 4.29 )2012年6月30日,也就今天晚上,时间会多出现一秒,也就是我们所说的闰秒。我不知道大家对闰秒的了解有多少,所以写下这篇文章。
闰秒是在在UTC(中文“世界标准时间”或“世界协调时间”/英文“Coordinated Universal Time”/法文“Temps Universel Cordonné”)是基于Atomic Clock(原子时钟)的一种时间,向太阳时(Solar Time )对齐的一种方法,因为太阳时是根据地球公转来计算的。所以,1972年制定的UTC为了确保其时间相对于UTC的时间误差不能超过0.9秒,因此在过一段时间后需要加一秒。下图是有UTC以来闰秒的调整表(来自Wikipedia闰秒的中文词条)

(13 人打了分,平均分: 4.08 )最近在学习一些数据挖掘的算法,看到了这个算法,也许这个算法对你来说很简单,但对我来说,我是一个初学者,我在网上翻看了很多资料,发现中文社区没有把这个问题讲得很全面很清楚的文章,所以,把我的学习笔记记录下来,分享给大家。
在数据挖掘中, k-Means 算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
K-Means算法主要解决的问题如下图所示。我们可以看到,在图的左边有一些点,我们用肉眼可以看出来有四个点群,但是我们怎么通过计算机程序找出这几个点群来呢?于是就出现了我们的K-Means算法(Wikipedia链接)

这个算法其实很简单,如下图所示:
(24 人打了分,平均分: 4.25 )【感谢 @常新居士 投递此文 】
这几年,持续集成随着敏捷在国内的推广而持续走热,与之相伴的持续部署也一直备受关注。自前两年,持续交付这个延续性概念又闯进了国内IT圈,慢慢开始在社区和会议中展露头角。许多不明真相的群众跟风哭着喊着要“上”,而许多前CI的半吊子玩家换件衣服就接着干,有的甚至衣服都来不及换……。国内的这些土财主如果不巧请了某些所谓的战略家,除了建了一堆持续集成环境,以及每天嚷嚷着要这个要那个,混乱的状况在根本上没有得到改善。本文无意费力探讨持续集成和持续交付的概念,而是打算谈谈对于大型软件企业,以持续集成为基础实现持续部署(交付)时,所要面对的问题以及可行的解决方案。地主老财们,夜黑风正猛,山高路又远,注意脚下……
And God Said, Let there be light: and there wa— GENSIS, Charpter 1, King James
先来讲个故事……
几年前,一对留美的夫妇通过朋友找到我,让我帮忙在国内组建一个开发团队,该团队负责为其开发一款基于社交网络的客户关系管理软件,(暂且称之为项目A)。这个项目除了尚不清晰的需求范围和很紧的期限外,作为业内人士的老公Richard根据眼下流行的软件开发过程还提了诸多额外的要求:
这正是持续集成所要解决的典型场景。针对Richard的要求,我们只要建立一个基于Hudson(现在叫Jenkins)+Maven +SVN 的持续集成环境(再加上持续集成所要求的测试和过程)就可以很好地满足上述要要求,此方案的结构如下:
(28 人打了分,平均分: 4.04 )原文:http://garmoncheg.blogspot.com/2012/06/pretty-git-log.html (墙)
Git的传统log如下所示,你喜欢吗?

看看下面这个你喜不喜欢?(点击图片看大图)
(15 人打了分,平均分: 4.07 ) 关于性能优化这是一个比较大的话题,在《由12306.cn谈谈网站性能技术》中我从业务和设计上说过一些可用的技术以及那些技术的优缺点,今天,想从一些技术细节上谈谈性能优化,主要是一些代码级别的技术和方法。本文的东西是我的一些经验和知识,并不一定全对,希望大家指正和补充。
关于性能优化这是一个比较大的话题,在《由12306.cn谈谈网站性能技术》中我从业务和设计上说过一些可用的技术以及那些技术的优缺点,今天,想从一些技术细节上谈谈性能优化,主要是一些代码级别的技术和方法。本文的东西是我的一些经验和知识,并不一定全对,希望大家指正和补充。
在开始这篇文章之前,大家可以移步去看一下宝酷以前发表的《代码优化概要》,这篇文章基本上告诉你——要进行优化,先得找到性能瓶颈! 但是在讲如何定位系统性能瓶劲之前,请让我讲一下系统性能的定义和测试,因为没有这两件事,后面的定位和优化无从谈起。
让我们先来说说如何什么是系统性能。这个定义非常关键,如果我们不清楚什么是系统性能,那么我们将无法定位之。我见过很多朋友会觉得这很容易,但是仔细一问,其实他们并没有一个比较系统的方法,所以,在这里我想告诉大家如何系统地来定位性能。 总体来说,系统性能就是两个事:
一般来说,一个系统的性能受到这两个条件的约束,缺一不可。比如,我的系统可以顶得住一百万的并发,但是系统的延迟是2分钟以上,那么,这个一百万的负载毫无意义。系统延迟很短,但是吞吐量很低,同样没有意义。所以,一个好的系统的性能测试必然受到这两个条件的同时作用。 有经验的朋友一定知道,这两个东西的一些关系:
经过上述的说明,我们知道要测试系统的性能,需要我们收集系统的Throughput和Latency这两个值。
(53 人打了分,平均分: 4.28 ) 很早就想写这篇文章了,只是想法比较零碎,所以一直没有成文,这两天觉得思考得比较成熟了一些,所以把我的这些想法整理下来,欢迎大家一起和我讨论。
很早就想写这篇文章了,只是想法比较零碎,所以一直没有成文,这两天觉得思考得比较成熟了一些,所以把我的这些想法整理下来,欢迎大家一起和我讨论。
首先,先表达我的立场,我对抄袭的立场持BS和痛恨的态度,尤其是那些C2C的网站,痛恨这些国外有什么就山寨什么的做法,尤其是那些连界面都不改,像素级的抄袭,连CSS和img都是一样的,更甚者,连图片都链接到抄袭源的网站去了,连源代码都抄的行为,比如:腾讯抄新浪的代码,新浪抄twitter的源码。无法不BS之。
有很多网友邀请我去那个抄袭Quora的网站上去回答问题,借此,再次声明我不会去的。因此,有一些网友说,我不一样也在Twitter的抄袭网站新浪微博上吗?说我装逼了。我想说,新浪和Twitter基本上是同一种产品的思路,但是其实现不一样,新浪微博上一些twitter上没有功能,我个人觉得这并不算抄袭,我甚至认为新浪微博和Twitter各有长处,在一些功能上新浪微博比twitter做得更好。你可以理解为,新浪微博总体上来说并没有突破我心中的那个条抄袭的底线。
我个人对抄袭的理解如下:
1)你可以复制别人的想法和功能,但是如果你连界面设计,代码,图片,风格,布局,等等所有的一切都照抄,那我就一定要鄙视你。
2)你可以仿照别人的产品,但是你的出发点应该是他没做好,我来把它把做好,如果你的出发点是为了复制抄袭和山寨,我一样鄙视。
所以,你可以理解我为什么不去Quora,Stackoverflow,Facebook,Google的山寨网站了,因为上述两点,1)完全复制,2)山寨地太次。
因为很多朋友极端地理解了我对抄袭的立场,所以我有必要要说说我对“抄袭”或是“模仿”的其它一些观点:
(60 人打了分,平均分: 4.72 )